-
Writing a Managed Internet Explorer Extension: Part 6 – Regrets
If you’ve followed my blog to any degree, you’ve probably found that I’ve written a few posts on Browser Helper Objects (BHOs) that actually got some attention. A BHO is Internet Explorer’s main mechanism way of extending the browser. Unlike any other browser, writing these is not trivial. They are COM objects, and either need to be written in native code, or managed code with lasses marked as COM Visible. A long time ago, I wrote a post titled, Writing a Managed Internet Explorer Extension: Part 1 – Basics. The first question I posted to myself was “Managed vs. Native”. Ultimately I decided that managed was the way I wanted to go:
The .NET Framework had another benefit to me, and that was WPF. My BHO requires an user interface, and doing that natively isn’t as easy or elegant as using native libraries. Ultimately I decided to go with .NET Framework 4.0, and I can only recommend the .NET Framework 4.
I sincerely regret my decision to go with managed code, and would encourage those at this crossroad to go with native.
Distribution
This BHO wasn’t a hobby. Distributing these things isn’t nearly as easy as any other browser. All others, Chrome, Safari, and Firefox, have hosted extension galleries. Even if you choose not to use a gallery, they all provide neat extension packages making installation trivial. Internet Explorer does not, so it was up to us to build an installer, handle all of the nuances between versions of Windows, handle different bitnesses correctly, etc. Writing the BHO in managed code introduced a dependency on the .NET Framework 4.0 Client Profile. Windows 8 is just on the horizon, and it is the first version of Windows to include a version of the CLR that can run the .NET Framework 4.0. By now, most organizations have hopefully deployed the .NET Framework 4, but it was an issue that never went away. “Why do I need a 50 megabyte framework for this?” I initially dismissed this, but it seemed like our customers actually cared.
Performance
By far though, the most troublesome part of it was the performance. The BHO itself was super light and simple with no complex functionality. It was the CLR itself that introduced problems. The load time, for example, could fluctuate between “instant” and “crawling”. Personally I never saw a load time take above a tenth of a second, however on some environments it would take up to a quarter (!) of a second. Internet Explorer will also use a process per-tab, so the extension needed to be loaded once for every tab. This means each tab took a quarter of a second to load in the worse cases. Internet Explorer will actually flag the extension as poor performance and give the user the option to disable it.
Just the example from the very beginning takes 0.03 seconds to load, on a good time.

The memory footprint wasn’t a good story either. Again, per-tab, the CLR can carry a 10 MB virtual memory footprint.
All of these may not be real deal breakers depending on your target audience. But for what? I wanted to use WPF to make a rich configuration option, but anything I wanted to do in managed code I could have done natively, it just wasn’t my comfort zone. Being comfortable should not cost the user anything.
At the end of it, I ended up rewriting the BHO in native code, and came up with a much cleaner, faster result. So please, for the users’ sake, stop writing BHOs in managed code.
As a side note, I find it interesting, and confusing, that the Internet Explorer team will tell you not to write a BHO in managed code, almost exactly for the reasons I decided not to (there is that “one CLR version per process problem”, but that is an old problem that has been fixed), yet MSDN is happy enough to provide examples on how to do it. There’s a big flag that there is a community that wants to write extensions for Internet Explorer, but the extensibility of Internet Explorer is so horrible that people are willing to use tools that are not recommended simply because its easier.
More of this series
- Writing a Managed Internet Explorer Extension: Part 1 – Basics
- Writing a Managed Internet Explorer Extension: Part 2 – DOM Basics
- Writing a Managed Internet Explorer Extension: Part 3
- Writing a Managed Internet Explorer Extension: Part 4 – Debugging
- Writing a Managed Internet Explorer Extension: Part 5 – Working with the DOM
- Writing a Managed Internet Explorer Extension: Part 6 – Regrets
-
Writing a Managed Internet Explorer Extension: Part 5 – Working with the DOM
Internet Explorer is known for having a quirky rendering engine. Most web developers are familiar with with concept of a rendering engine. Most know that Firefox uses Gecko, and Chrome / Safari use WebKit (update: Opera uses WebKit ow too!). WebKit itself has an interesting history, originally forked from the KHTML project by Apple. However pressed, not many can name Internet Explorer’s engine. Most browsers also indicate their rendering engine in their User Agent. For example, my current Chrome one is “Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.7 (KHTML, like Gecko) Chrome/7.0.517.44 Safari/534.7” Not as many web developers could name Internet Explorer’s, it was simply referred to as “Internet Explorer”. The actual name of IE’s rendering engine is Trident. It’s been part of Internet Explorer since 4.0 – it was just deeply integrated nto Internet Explorer. At it’s heart, Trident lives in the mshtml.dll and shdocvw.dll libraries in the system32 directory. Earlier, you referenced these libraries as a COM type library.
When accessing IE’s DOM from a BHO, it’s in some regards very similar to doing it from JavaScript. It has the familiar
getElementById, and the rest of the gang. You’re also constrained, like JavaScript, by the minimum version of IE you plan to support with your BHO. If your BHO is going to be commercial, it isn’t unreasonable to still support IE6. In many respects, you will be using OLE Automation to manipulate the DOM.Like JavaScript, it is desirable to know what version of IE you are working against. Many JavaScript developers will tell you it’s poor practice to code against versions of a browser, but rather test if the feature is available in a browser. That keeps the JavaScript agnostic to the browser. However, we know we are just coding against IE. I have no strong recommendation one way or the other, but I’ll show you both. This is probably the simplest way to just get IE’s version:
var version = Process.GetCurrentProcess().MainModule.FileVersionInfo;That provides a plethora of information about IE’s version. The ProductMajorPart will tell you if it’s 6, 7, or 8. There are many other details in there – it can tell you if it’s a debug build, the service pack, etc. You may have surmised hat if JavaScript can do it, then we can do it the same way JavaScript does using the appVersion property. Before you start going crazy looking for it on the IWebBrowser2 interface though – I’ll tell you it’s not there. Nor is it on any of the HTMLDocument interfaces. It has it’s own special interface, called
IOmNavigator. That interface is defined in mshtml.dll – so since you have already referenced that Type Library you should already have access to it – but how do I get an instance of that thing?It isn’t difficult, but there is where the interface complexity has it’s disadvantages.
IOmNavigatoris on the window, and theIHTMLDocument2interface can provide a path to the window.var document = (IHTMLDocument2) _webBrowser2; var appVersion = document.parentWindow.navigator.appVersion;However, if we wanted to do the right thing and test for feature availability rather than relying on version numbers, how do we do that?
The most straightforward is determining which interfaces an object supports. Most of your DOM work is going to be done through the Document property off of WebBrowser2. This is of type HTMLDocument, but there are several different interfaces available. Every time a change was made to the Document API, a new interface was created to maintain backward compatibility (Remember COM uses Interface Querying, so it makes more sense in that respect.)
In .NET we can do something similar using the “is” keyword.
private void _webBrowser2Events_DocumentComplete(object pdisp, ref object url) { if (!ReferenceEquals(pdisp, _pUnkSite)) { return; } if (_pUnkSite.Document is IHTMLDocument5) { //IHTMLDocument5 was introduced in IE6, so we are at least IE6 } }There are a several IHTMLDocumentX interfaces, currently up to
IHTMLDocument7which is part of IE9 Beta.WAIT! Where is IHTMLDocument6?
The MSDN Documentation for IHTMLDocument6 says it’s there for IE 8. Yet there is a good chance you won’t see it even if you have IE 8 installed.
This is a downside of the automatically generated COM wrapper. If you look at the reference that says MSHTML, and view it’s properties, you’ll notice that its Path is actually in the GAC, something like this:
C:\Windows\assembly\GAC\Microsoft.mshtml\7.0.3300.0__b03f5f7f11d50a3a\Microsoft.mshtml.dllMicrosoft Shipped a GAC’ed version of this COM wrapper, which is used within the .NET Framework itself. However, the one in the GAC is sorely out-of-date. We can’t take that assembly out of the GAC (or risk a lot of problems).
What to do?
We are going to manually generate a COM wrapper around MSHTML without the Add Reference Dialog. Pop open the Visual Studio 2010 Command Prompt. The tool we will be using is part of the .NET Framework SDK, called tlbimp.
The resulting command should look something like this:
tlbimp.exe /out:mshtml.dll /keyfile:key.snk /machine:X86 mshtml.tlbThis will generate a new COM wrapper explicitly and write it out to mshtml.dll in the current working directory. The keyfile switch is important – it should be strong name signed, and you should already have a strong name key since it is required for regasm. mshtml.tlb is a type library found in your system32 directory. This new generated assembly will contain the IHTMLDocument6 interface, as we expect. If you have IE 9 beta installed, you will see IHTMLDocument7 as well. NOTE: This is a pretty hefty type library. It might take a few minutes to generate the COM Wrapper. Patience.
If you are happy just being able to access the DOM using IE 6’s interfaces, then I wouldn’t bother with this. There are advantages to using the one in the GAC (smaller distributable, etc).
In summary, you have two different means of detecting a browser’s features. Using the version by getting the version of the browser, or testing if an interface is implemented. I would personally recommend testing against interfaces, because there is always a tiny chance that Microsoft may remove functionality in a future version. It’s doubtful for the IHTMLDocument interfaces, however for other things it’s a reality.
Now that we have a way of knowing what APIs are at our disposal, we can manipulate the DOM however you see fit. There isn’t much to explain there – if you think it’s hard, it’s probably because it is. It’s no different that trying to do it in JavaScript.
This is an extremely resourceful page when trying to figure out which interface you should be using based on a markup tag: https://msdn.microsoft.com/en-us/library/aa741322(v=VS.85).aspx.
More of this series
- Writing a Managed Internet Explorer Extension: Part 1 – Basics
- Writing a Managed Internet Explorer Extension: Part 2 – DOM Basics
- Writing a Managed Internet Explorer Extension: Part 3
- Writing a Managed Internet Explorer Extension: Part 4 – Debugging
- Writing a Managed Internet Explorer Extension: Part 5 – Working with the DOM
- Writing a Managed Internet Explorer Extension: Part 6 – Regrets
-
Writing a Managed Internet Explorer Extension: Part 4 – Debugging
Picking up where we left of with Writing a Managed Internet Explorer Extension, debugging is where I wanted to go next. I promise I’ll get to more “feature” level stuff, but when stuff goes wrong, and it will, you need to know how to use your toolset. .NET Developers typically write some code and press F5 to see it work. When an exception, the debugger, already attached, steps up to the plate and tells you everything that is wrong. When you write an Internet Explorer Extension it isn’t as simple as that. You need to attach the debugger to an existing process, and even then it won’t treat you like you’re use to. Notably, breakpoints aren’t going to launch the debugger until the debugger is already attached. So we have a few options, and some tricks up our sleeves, to get the debugger to aide us.
Explicit Breakpoints
The simplest way to emulate a breakpoint is to put the following code in there:
System.Diagnostics.Debugger.Break()Think of that as a breakpoint that is baked into your code. One thing to note if you’ve never used it before is that the Break method has a
[Conditional(“DEBUG”)]attribute on it – so it’ll only work if you are compiling in Debug. When this code gets hit, a fault will occur. It will ask you if you want to close, or attach a debugger. Now is your opportunity to say “I want a debugger!” and attach.It’ll look like just a normal Internet Explorer crash, but if you probe at the details, “Problem Signature 09” will tell you if it’s a break. When working on a BHO, check this every time IE “crashes” – it’s very easy to forget that these are in there. It’s also important that you compile in Release mode when releasing to ensure none of these sneak out into the wild. The user isn’t going to look at the details and say, “Oh it’s just a breakpoint. I’ll attach and hit ‘continue’ and everything will be OK”. Once that’s done, choose Visual Studio as your debugger of choice (more on that later) and you should feel close to home.
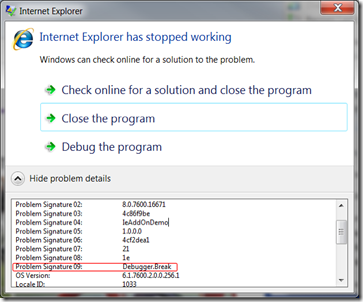
This is by far one of the easiest ways to attach a debugger, the problem with it is it requires a code change to get working, meaning you need to change the code, close all instances of IE, drop in the new DLL, restart Internet Explorer, and get it back into the state it was. A suggestion would be to attach on
SetSitewhen the site isn’t null. (That’s when the BHO is starting up. Refresher here.) That way, your debugger is always attached throughout the lifetime of the BHO. The disadvantage of that is it’s get intrusive if you like IE as just a browser. You can always Disable the extension or run IE in Safe Mode when you want to use it as an actual browser. If you take this approach, I recommend usingDebugger.Launch(). I’ll leave you to the MSDN Documents to understand the details, but Launch won’t fault the application, it will skip straight to the “Which debugger do you want to use?” dialog.Attaching to an Existing Process
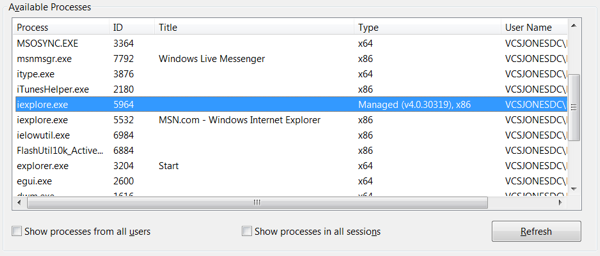
You can just as well attach to an existing process like you normally would, but there is one drawback: “Which process do I want to attach to?” In IE 8 that is a question that can be difficult to answer. Each tab has it’s own process (a trend in new generation browsers – IE was the first to support it). You will have at minimum of two IE processes. One for each tab, and one per actual instance of IE acting as a conductor for the other processes. Already, with just a single tab open, you have a 50/50 chance of getting it right if you guess. Visual Studio can give us some help though. If you pull up the Attach to Process Dialog, you should see your two instances of IE. The “Type” column should give it away. We want the one with Managed code in it (after all, the title of this blog series is “Writing a Managed Extension”).
Once you’re attached, you can set regular breakpoints the normal way and they’ll get hit.
It isn’t quite as easy when you have multiple tabs open – sometimes that’s required when debugging a tricky issue. You have a few options here:
- When building a UI for your BHO (It’s a catch 22 – I know I haven’t gotten there yet) have it display the PID of the current process. That’s easy enough to do using the Process class. You can dumb it down a little more though and write a log file in a safe location (IE is picky where BHOs write to the File System Refresher here).
- Attach to all tab processes. That can lead to a lot of confusion of which tab you are currently in, because if you have two tabs open – and a breakpoint gets hit – which tab did it? The Threads Window should help you there if that is the route you choose.
- Always debug with a single tab, if you can.
More of this series
- Writing a Managed Internet Explorer Extension: Part 1 – Basics
- Writing a Managed Internet Explorer Extension: Part 2 – DOM Basics
- Writing a Managed Internet Explorer Extension: Part 3
- Writing a Managed Internet Explorer Extension: Part 4 – Debugging
- Writing a Managed Internet Explorer Extension: Part 5 – Working with the DOM
- Writing a Managed Internet Explorer Extension: Part 6 – Regrets
-
Writing a Managed Internet Explorer Extension: Part 3
I’m debating where to take this little series, and I think I am at a point where we need to start explaining Internet Explorer, and why writing these things can be a bit tricky. I don’t want to write a blog series where people are blindly copying and pasting code and not knowing what IE is doing.
I am not a professional at it, but I’ve written browser extensions for most popular browsers. IE, Chrome, Firefox, and Safari. In terms of difficulty, IE takes it. That’s probably why there isn’t a big extension community for IE.
IE at it’s pinnacle, IE was 95% by web surfers with IE 5 and IE 6. If you are a developer, you probably hear a lot of criticisms for IE 6, and rightly so. Back then, IE supported a plug in model with that notorious name ActiveX. It was criticized for allowing web pages to just ship run arbitrary code. Of course, all of that changed and now IE really gets in your face before one of those things run. In fact, it is one of the reasons why intranet apps still require IE 6. Regardless, the message was clear to Microsoft. We need security!
Security was addressed in IE 7, and even more so in IE 8 with the help of Windows Vista and Windows 7.
Hopefully by now you’ve had the opportunity to play around with writing IE Add Ons, but you may have noticed some odd behavior, such as accessing the file system.
UAC / Integrity Access
UAC (User Access Control) was introduced in Windows Vista. There was a lot of noise over it, but it does make things more secure, even if that lousy dialog is turned off. It’s just transparent to the user. The purpose of UAC is the Principle of Least Privilege. Don’t give a program access to a securable object, like a file, unless it needs access to it. Even if your application will never touch a specific file, another application might figure out a way to exploit your application into doing dirty deeds for it. UAC provides a mechanism for temporarily giving access to securable object the application would normally not have permission to. UAC introduced the concept of Elevated and Normal. Normal is what the user normally operates under until a UAC prompt shows up.
Those two names are just used on the surface though… there are actually three Integrity Access Levels. Aptly named, they are called Low, Medium, and High. Medium is Normal, and High is Elevated.
IE is a program that use Low by default. Low works just like threads and process tokens. In theory, you could run your own application in “Low”. Low is it’s own SID: “S-1-16-4096”. If we start a process using this SID, then it will be low integrity. You can see this article for a chunk of code that does that. It’s hard to do this in managed code, and will require a good amount of platform invoke. You can also use this technique with threads.
Ultimately, Low mode has some really hard-core security limitations. You have no access to the File System, except a few useful places
- %USERPROFILE%\Local Settings\Temporary Internet Files\Low
- %USERPROFILE%\Local Settings\Temp\Low
- %USERPROFILE%\AppData\LocalLow
- %USERPROFILE%\Cookies\Low
- %USERPROFILE%\Favorites\Low
- %USERPROFILE%\History\Low
That’s it. No user documents, nada. Some of those directories may not even exist if a Low process hasn’t attempted to create them yet. If your extension is going to only be storing settings, I recommend putting them into %USERPROFILE%\AppData\LocalLow. This directory only exists in Windows Vista and up. Windows XP has no UAC, and also it has no protected mode, so you are free to do as you please on Windows XP.
To determine that path of LocalLow, I use this code. A domain policy might move it elsewhere, or it might change in a future version of Windows:
read more... -
Writing a Managed Internet Explorer Extension: Part 2 – DOM Basic
Continuing my miniseries from Writing a Managed Internet Explorer Extension: Part 1 – Basics, we discussed how to setup a simple Internet Explorer Browser Helper Object in C# and got a basic, but somewhat useless, example working. We want to interact with our Document Object Model a bit more, including listening for events, like when a button was clicked. I’ll assume that you are all caught up on the basics with my previous post, and we will continue to use the sample solution.
Elements in the
HTMLDocumentcan be accessed bygetElementById,getElementsByName, orgetElementsByTagName, etc. We’ll usegetElementsByTagName, and then filter that based on their “type” attribute of “button” or “submit”.An issue that regularly comes up with using the generated .NET MSHTML library is its endless web of delegates, events, and interfaces. Looking at the object explorer, you can see that there are several delegates per type. This makes it tricky to say “I want to handle the ‘onclick’ event for all elements.” You couldn’t do that because there is no common interface they all implement with a single onclick element. However, if you are brave you can let dynamic types in .NET Framework 4.0 solve that for you. Otherwise you will have a complex web of casting ahead of you.
Another issue that you may run into is conflicting member names. Yes, you would think this isn’t possible, but the CLR allows it, I just don’t believe C# and VB.NET Compiles allow it. For example, on the interface HTMLInputElement, there is a property called “onclick” and an event called “onclick”. This interface will not compile under C# 4:
public interface HelloWorld { event Action HelloWorld; string HelloWorld { get; } }However, an interesting fact about the CLR is it allows methods and properties to be overloaded by the return type. Here is some bare bones MSIL you can compile on your own using ilasm to see it in action:
.assembly extern mscorlib { .publickeytoken = (B7 7A 5C 56 19 34 E0 89 ) .ver 4:0:0:0 } .module MsilExample.dll .imagebase 0x00400000 .file alignment 0x00000200 .stackreserve 0x00100000 .subsystem 0x0003 .corflags 0x0000000b .class interface public abstract auto ansi MsilExample.HelloWorld { .method public hidebysig newslot specialname abstract virtual instance void add_HelloWorld (class [mscorlib]System.Action 'value') cil managed { } .method public hidebysig newslot specialname abstract virtual instance void remove_HelloWorld (class [mscorlib]System.Action 'value') cil managed { } .method public hidebysig newslot specialname abstract virtual instance string get_HelloWorld() cil managed { } .event [mscorlib]System.Action HelloWorld { .addon instance void MsilExample.HelloWorld:: add_HelloWorld(class [mscorlib]System.Action) .removeon instance void MsilExample.HelloWorld:: remove_HelloWorld(class [mscorlib]System.Action) } .property instance string HelloWorld() { .get instance string MsilExample.HelloWorld::get_HelloWorld() } }That MSIL isn’t fully complete as it lacks any sort of manifest, but it will compile and .NET Reflector will be able to see it. You might have trouble referencing it from a C# or VB.NET project.
You can work around this issue by being explicit in this case: cast it to the interface to gain access to the event or do something clever with LINQ:
void _webBrowser2Events_DocumentComplete(object pDisp, ref object URL) { HTMLDocument document = _webBrowser2.Document; var inputElements = from element in document.getElementsByTagName("input").Cast() select new { Class = element, Interface = (HTMLInputTextElementEvents2_Event)element }; foreach (var inputElement in inputElements) { inputElement.Interface.onclick += inputElement_Click; } } static bool inputElement_Click(IHTMLEventObj htmlEventObj) { htmlEventObj.cancelBubble = true; MessageBox.Show("You clicked an input element!"); return false; }This is pretty straight forward: whenever the document is complete, loop through all of the input elements and attach on onclick handler to it. Despite the name of the interface, this will work with all HTMLInputElement objects.
Great! We have events wired up. Unfortunately, we’re not done. This appears to work at first try. However, go ahead and load the add on and use IE for a while. It’s going to start consuming more and more memory. We have written a beast with an unquenchable thirst for memory! We can see that in WinDbg, too.
MT Count TotalSize Class Name 03c87ecc 3502 112064 mshtml.HTMLInputTextElementEvents2_onclickEventHandler 06c2aac0 570 9120 mshtml.HTMLInputElementClass This is a bad figure, because it is never going down, even if we Garbage Collect. With just a few minutes of use of Internet Explorer, there is a huge number of event handles. The reason being because we never unwire the event handler, thus we are leaking events. We need to unwire them. Many people have bemoaned this problem in .NET: event subscriptions increment the reference count. Many people have written Framework wrappers for events to use “Weak Events”, or events that don’t increment the reference count. Both strong and weak reference have their advantages.
I’ve found the best way to do this is to keep a running Dictionary of all the events you subscribed to, and unwire them in BeforeNavigate2 by looping through the dictionary, then removing the element from the dictionary, allowing it to be garbage collected.
Here is my final code for unwiring events:
[ComVisible(true), Guid("9AB12757-BDAF-4F9A-8DE8-413C3615590C"), ClassInterface(ClassInterfaceType.None)] public class BHO : IObjectWithSite { private object _pUnkSite; private IWebBrowser2 _webBrowser2; private DWebBrowserEvents2_Event _webBrowser2Events; private readonly Dictionary < HTMLInputTextElementEvents2_onclickEventHandler, HTMLInputTextElementEvents2_Event > _wiredEvents = new Dictionary < HTMLInputTextElementEvents2_onclickEventHandler, HTMLInputTextElementEvents2_Event >(); public int SetSite(object pUnkSite) { if (pUnkSite != null) { _pUnkSite = pUnkSite; _webBrowser2 = (IWebBrowser2)pUnkSite; _webBrowser2Events = (DWebBrowserEvents2_Event)pUnkSite; _webBrowser2Events.DocumentComplete += _webBrowser2Events_DocumentComplete; _webBrowser2Events.BeforeNavigate2 += _webBrowser2Events_BeforeNavigate2; } else { _webBrowser2Events.DocumentComplete -= _webBrowser2Events_DocumentComplete; _webBrowser2Events.BeforeNavigate2 -= _webBrowser2Events_BeforeNavigate2; _pUnkSite = null; } return 0; } void _webBrowser2Events_BeforeNavigate2(object pDisp, ref object URL, ref object Flags, ref object TargetFrameName, ref object PostData, ref object Headers, ref bool Cancel) { foreach (var wiredEvent in _wiredEvents) { wiredEvent.Value.onclick -= wiredEvent.Key; } _wiredEvents.Clear(); } void _webBrowser2Events_DocumentComplete(object pDisp, ref object URL) { HTMLDocument document = _webBrowser2.Document; var inputElements = from element in document.getElementsByTagName("input").Cast() select new { Class = element, Interface = (HTMLInputTextElementEvents2_Event)element }; foreach (var inputElement in inputElements) { HTMLInputTextElementEvents2_onclickEventHandler interfaceOnOnclick = inputElement_Click; inputElement.Interface.onclick += interfaceOnOnclick; _wiredEvents.Add(interfaceOnOnclick, inputElement.Interface); } } static bool inputElement_Click(IHTMLEventObj htmlEventObj) { htmlEventObj.cancelBubble = true; MessageBox.Show("You clicked an input!"); return false; } public int GetSite(ref Guid riid, out IntPtr ppvSite) { var pUnk = Marshal.GetIUnknownForObject(_pUnkSite); try { return Marshal.QueryInterface(pUnk, ref riid, out ppvSite); } finally { Marshal.Release(pUnk); } } }After performing the same level of stress as before, there were only 209 instances of HTMLInputTextElementEvents2_onclickEventHandler. That is still a bit high, but it’s because the Garbage Collector done it’s cleanup. The Garbage Collector makes it a bit subjective to counting how many objects are in memory.
There are alternative ways to wire events. If the strong typing and plethora of interfaces is getting to you, it’s possible to use attachEvent and detachEvent albeit it requires converting these events into objects that COM can understand.
More of this series
- Writing a Managed Internet Explorer Extension: Part 1 – Basics
- Writing a Managed Internet Explorer Extension: Part 2 – DOM Basics
- Writing a Managed Internet Explorer Extension: Part 3
- Writing a Managed Internet Explorer Extension: Part 4 – Debugging
- Writing a Managed Internet Explorer Extension: Part 5 – Working with the DOM
- Writing a Managed Internet Explorer Extension: Part 6 – Regrets